I saw this post about closing an OJS site and thought one solution to this problem, and others, would be for OJS to be able to export a site into markdown files for use by a static site generator. I use Hugo, but Jekyll is also popular.
Use Cases
Shutting down a site. The journal admin would export each page to a markdown, generate a static version of the journal website using their preferred static site generator and then archive the site to a CDN or small webserver. A static site can be hosted more cheaply than a mirror of a PHP site because content is just fetched. Low-medium traffic hosting for static sites is often available for free.
Separating journal front-end and back-end. Many publishers use separate systems for submissions and serving content to end users. Exporting journal content for a static site generator would allow admins to maintain availability of the front-end and journal content, even if the back-end is temporarily unavailable (e.g. while upgrading).
Site tuning for users who are not logged in. Similarly, serving static content to users who are not logged in can usually be faster than serving dynamic content. For example, static content is more easily cached across CDNs, so small single-origin journal site would be able to enjoy a speed boost by using a CDN, while using the dynamic OJS back-end for submissions.
Function
Similar to current export and backup plugins, a static site export plugin would need to export
Markdown files for each page on the journal site, including each article, article galley, and other pages (e.g. about the journal, submission guidelines).
Galley files
Website images
This would give an admin the content they would need to run a static site generator over their journal which would generate all the HTML files and structure according to the chosen/designed theme.
OJS (and other 3.x releases of PKP software) supports separating the publication of content from the backend workflow. See: Settings → Distribution → Access.
This is primarily used when OJS is being used just for the workflow, and the reviewed and proofed galleys will be manually posted elsewhere. Others do, however, utilize the API to present the published content in a front end UI outside of the OJS reader interface. One intent of the API is to allow this to be done dynamically or in periodic tooling, which would facilitate what you describe.
Another approach would be use a purpose-built tool overtop of OJS, such as in-place web server caching, or, such as web scraping and caching, to improve native performance or to create a static copy. Such tools are independent of target site architecture. For scholarly publishing in particular, though, note that in the event of a site shutting down, this is exactly what LOCKSS does.
The scenario of hosting both a PHP-enabled server and a static copy of the site is, I think, fairly niche, but it sounds like there is some existing momentum around it. Please do continue the conversation here in sharing what you have already done. We’re happy to help connect any potential contributors with guidance within the PKP framework, and I think any gaps within the API for making this possible would be of interest to core PKP developers.
Thanks, I have been working on porting the health sciences theme so to Hugo. It is available in a Github repository here and I’m using it to run a static mirror whose repository is here.
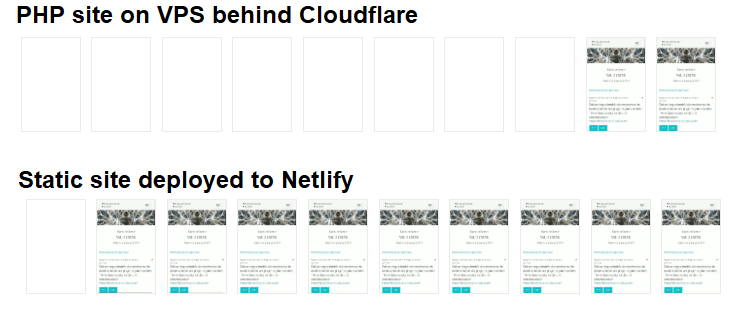
It is a good way for us to go as a free open access startup because we can combine it with CDNs to deliver fast loading times and guaranteed availability at no additional cost. For example, the traces below from Chrome developer tools shows a mobile test for the PHP site, which is behind Cloudflare, and the same test for the static mirror deployed to Netlify (both CDNs used on their free service tiers).
As noted, we could just switch off our journal front-end in OJS and set up some redirects for our existing articles, but it would leave a few challenges.
OAI Repository. Even if the site is set to do workflow only, the OAI repository still lists the resource identifier and relations as the OJS URL and galleys. We would need a way to tell the OAI repository the location of the article’s resources.
PKP PLN preservation. Would we still be able to join PKP PLN if we are not using OJS for the journal front end? I can see OJS not being able to send the content from external locations to PLN, but if those files are also uploaded to OJS, would it then be able to preserve them in PLN when the plugin becomes available?
I don’t know much about how to use the API, but it is something I will look into more.
The OAI question is interesting. If you list the published materials as Remote Galleys in OJS, I would expect OJS’s OAI to correctly point to those via relations, but I don’t think there is way to redefine within OJS the identifer as pointing to another abstract page. This would probably be best suited as a plugin to enable a “remote” for the identfier/abstract.
For the PLN, the way this plugin operates is a bit different than scraping based LOCKSS systems. Rather than harvesting the public presentation to store in LOCKSS, the PLN harvests article/issue exports from OJS. So, any metadata and uploaded publication files are captured within the PLN, regardless of whether OJS is used for distribution.
I tried out the effect of an external location in article galleys in OJS 3.1.1.2 - if you define an external location for a galley the OAI repository will still list the OJS URL in the OAI repository. If you are logged in and visit it, it will redirect you to the external galley. If you are not logged in, it will show you a login page.
With respect to PLN participation OJS won’t let you upload a file if you specify an external location. So a plugin would need to enable a remote URL for the identifier that links to the article abstract landing page but also to allow an article galley to have files that OJS can preserve and have an external URL for the OAI repository to point to.
So if I understand everything correctly, looking at the API and is the way to get started with building a workflow for getting the metadata out of OJS to publish articles on a separate front-end and a plugin is needed to enable remote URLs for the identifier/abstract and for the galleys. If that can be done, then anyone can host their content remotely while using OJS to handle submissions, expose metadata via OAI (and I assume the other metadata export plugins like Crossref and DOAJ would send the same URLs as OAI), and eventually upload content for preservation in PLN.
As @ctgraham already mentioned in the above discussion, If you are more into python, you can also use the python DAL , which I wrote for OMP a little modified for OJS and have full control yourself.