Dear PKP Team, and fellows in the community,
Our content was smoothly indexed by Google Scholar, even on sunday 24 November we still noticed some new indexed published content updates in Google-Scholar. However, starting on Monday, November 25, we noticed that all of our previously indexed content has disappeared from the platform, as if it no longer exists.
and now there is only one recored from researchgate here when searching soapubs.com
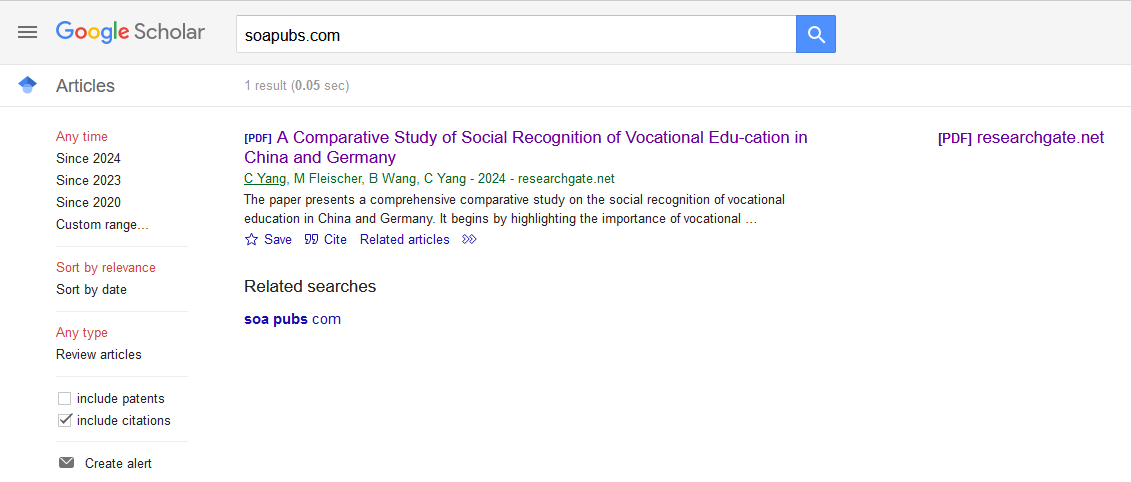
For reference, here is the link to our website: https://soapubs.com, and here are a few examples of our published content:
https://soapubs.com/index.php/EI/article/view/161
https://soapubs.com/index.php/MI/article/view/40
https://soapubs.com/index.php/IJLAI/article/view/46
We have thoroughly checked our setup and confirmed that our metadata complies with Google Scholar’s requirements. We are using Open Journal Systems (OJS), and the Googlebot is able to access our pages in under 10 seconds. We also ensure that each article has proper links to the abstract, PDF, and other relevant content.
Besides, There is something I want to clarify, I added some codes to the custom header plugin’s footer content, aiming to changed text ‘affiliation’ to text ‘phone number’ shown in the author registration stage, the reason I mentioned this is that because after this action all content can not be found in GS, so I guess this might be the reason
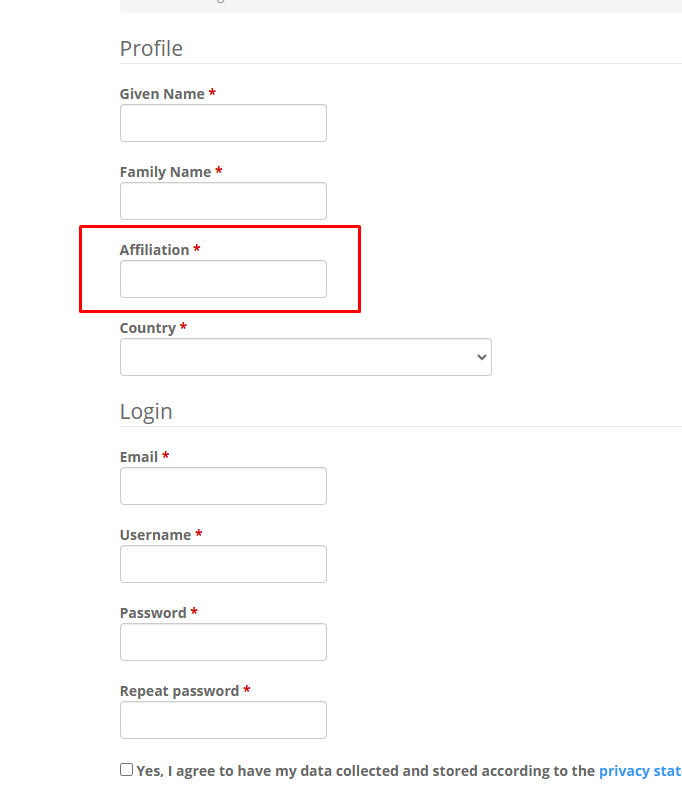
The codes is detailed below:
script type=“text/javascript”>
document.addEventListener(‘DOMContentLoaded’, function() {
// Find the affiliation label
var affiliationLabel = document.querySelector(‘.form-group.affiliation label’);
// Make sure the label exists
if (affiliationLabel) {
// Directly modify the text content of the label to “Phone Number”
affiliationLabel.innerHTML = affiliationLabel.innerHTML.replace(“Affiliation”, “Phone Number”);
} else {
console.error(“Affiliation label not found”);
}
});
script type=“text/javascript”>
document.addEventListener(‘DOMContentLoaded’, function() {
// Find the .label label inside affiliation
var affiliationLabel = document.querySelector(‘.affiliation .label’);
// Make sure .label label exists
if (affiliationLabel) {
// Only modify the text content of “Affiliation” to “Phone Number”
var labelTextNode = affiliationLabel.childNodes[0]; // Get the first child node (text node)
if (labelTextNode && labelTextNode.nodeType === Node.TEXT_NODE) {
labelTextNode.textContent = "Phone Number ";
}
} else {
console.error(“Affiliation label not found”);
}
});
Could you and the PKP team kindly help us understand the root cause of this issue? If there is anything further we can do to resolve it or any suggestions to get our content re-indexed, we would greatly appreciate your guidance.