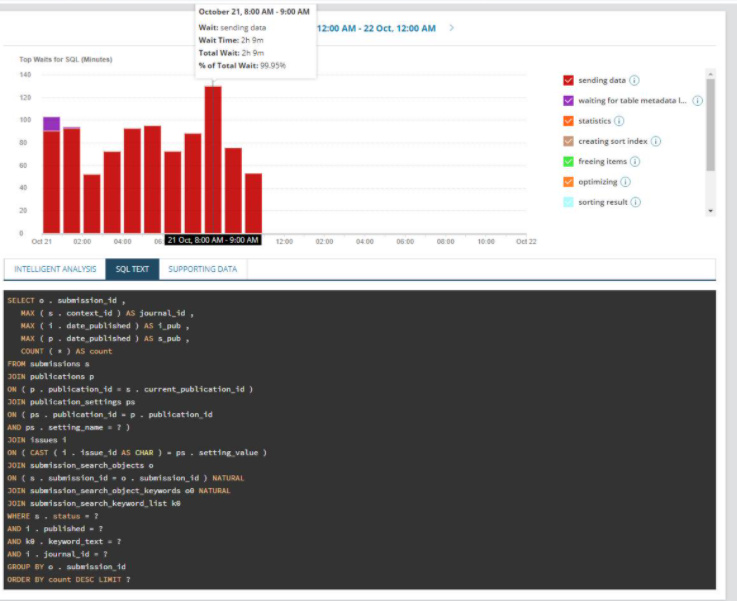
We’ve been seeing that our database takes too long to make a response to some querys like this one:
SELECT o.submission_id,
MAX(s.context_id) AS journal_id,
MAX(i.date_published) AS i_pub,
MAX(p.date_published) AS s_pub,
COUNT(*) AS count
FROM
submissions s
JOIN publications p ON (p.publication_id = s.current_publication_id)
JOIN publication_settings ps ON (ps.publication_id = p.publication_id AND ps.setting_name='issueId')
JOIN issues i ON (CAST(i.issue_id AS CHAR) = ps.setting_value)
JOIN submission_search_objects o ON (s.submission_id = o.submission_id)
NATURAL JOIN submission_search_object_keywords o0 NATURAL JOIN submission_search_keyword_list k0
WHERE
s.status = 3 AND
i.published = 1 AND k0.keyword_text = 'los' AND i.journal_id = 7
GROUP BY o.submission_id
ORDER BY count DESC
LIMIT 500
The system is taking from 20 to 30+ seconds to respond, and sometimes it even hangs and the OJS stops working for more than 3 minutes.
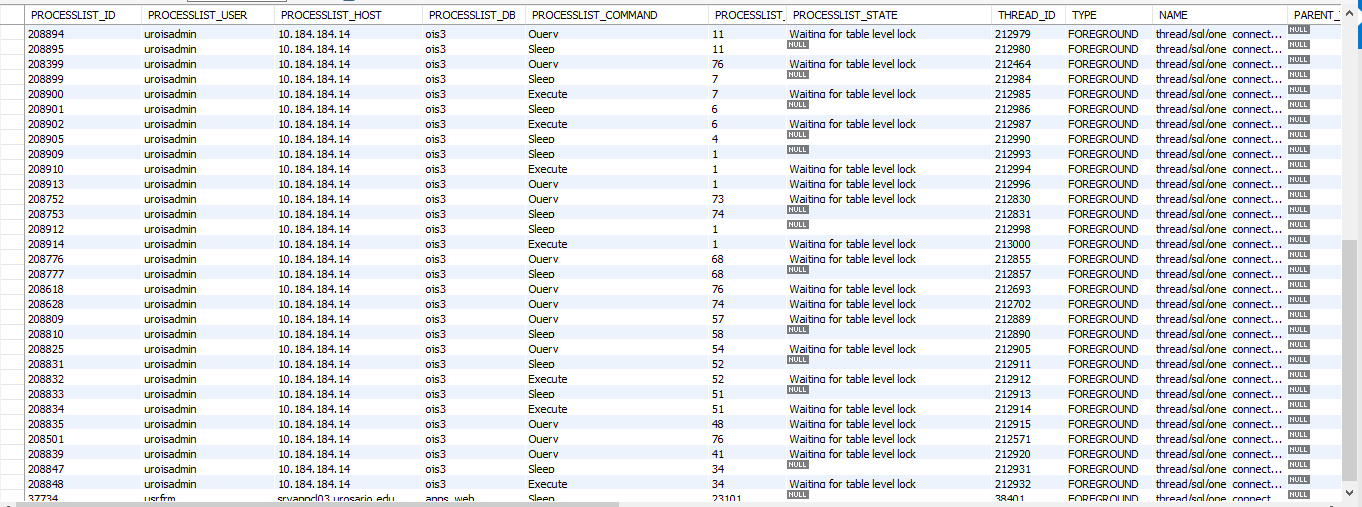
If you’re seeing a lot of simultaneous queries like this, it’s possible that a bot is hitting the search page and causing your database to bog down. I’d suggest looking through your request log to see if you can spot the corresponding “search” requests. If there appear to be an unreasonable number coming e.g. from one or two sources, you may need to investigate that.
Regards,
Alec Smecher
Public Knowledge Project Team
That’s a web server (fcgi) message, not an OJS message, but it indicates that your pool of PHP processes can’t keep up with the number of requests. Since several of these reference Google, you should be able to slow down indexing using robots.txt.
Regards,
Alec Smecher
Public Knowledge Project Team
Did you look through the access log for evidence of aggressive indexing of the search page? If that’s still happening, you’ll need to throttle it using e.g. robots.txt.
Regards,
Alec Smecher
Public Knowledge Project Team
Our Tech team is asking if there are a “best practice” documentation about the OJS 3.2 configuration, due to the facts that:
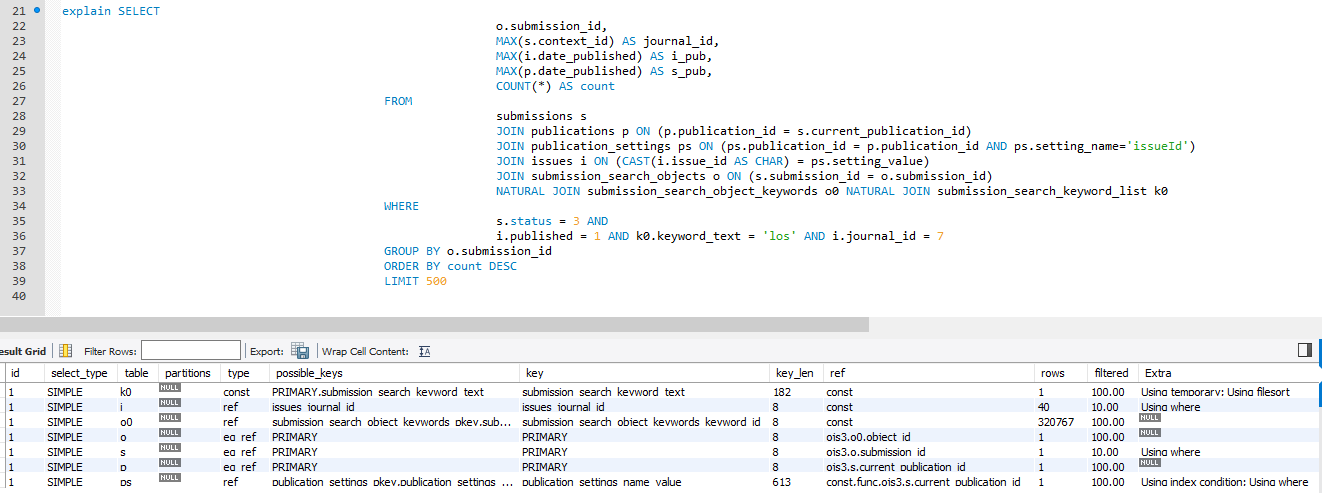
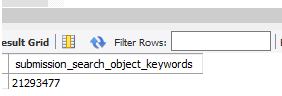
the table submission_search_object_keywords It has more than 21 million records of which it stores all the possible words by which they can make a query, for example “the”, etc …, of which when applying the where for these common words brings between 300 thousand to 2,000 records all depending on how common the search word is, I do not know if the community can ask how to narrow down the search criteria since as I mentioned the table has a considerable volume of records and when performing a query by a value as common as “the”, makes the query not as optimal as you would expect.
On the other hand and not least, it is observed that the database does not have a MER any relationship between the tables, although the tables have created the keys and indexes, for a database the relationships are essential, otherwise the The performance of the queries will be greatly affected, even more so when functions such as the natural join are used (for example, the expensive query that is identified uses it 2 times), since this function (natural join) identifies the relationships between tables and crosses them by the constraints created without having to specify in the query which are the keys, I would appreciate to escalate this issue to the community and know how they have mitigated it.
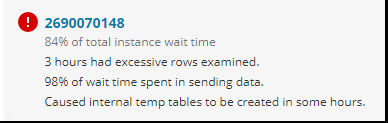
Our monitoring system shows the following about the database:
Time in minutes of the duration of the mentioned query.
*************************************************************************************************
*************************************** initial query ********************************************
*************************************************************************************************
SELECT
o.submission_id ,
MAX ( s.context_id ) AS journal_id ,
MAX ( i.date_published ) AS i_pub ,
MAX ( p.date_published ) AS s_pub ,
COUNT(*) AS count
FROM submissions s
JOIN publications p ON ( p.publication_id = s.current_publication_id )
JOIN publication_settings ps ON ( ps.publication_id = p.publication_id AND ps.setting_name = ? )
JOIN issues i ON (CAST(i.issue_id AS char) = ps.setting_value )
JOIN submission_search_objects o ON ( s.submission_id = o.submission_id )
NATURAL JOIN submission_search_object_keywords o0
NATURAL JOIN submission_search_keyword_list k0
WHERE s.status = ?
AND i.published = ?
AND k0.keyword_text = ?
AND i.journal_id = ?
GROUP BY o.submission_id
ORDER BY count DESC LIMIT ?;
*************************************************************************************************
************************************* example with params ***************************************
*************************************************************************************************
SELECT
o.submission_id,
MAX(s.context_id) AS journal_id,
MAX(i.date_published) AS i_pub,
MAX(p.date_published) AS s_pub,
COUNT(*) AS count
FROM
submissions s
JOIN publications p ON (p.publication_id = s.current_publication_id)
JOIN publication_settings ps ON (ps.publication_id = p.publication_id AND ps.setting_name='issueId')
JOIN issues i ON (CAST(i.issue_id AS CHAR) = ps.setting_value)
JOIN submission_search_objects o ON (s.submission_id = o.submission_id)
NATURAL JOIN submission_search_object_keywords o0
NATURAL JOIN submission_search_keyword_list k0
WHERE
s.status = 3 AND
i.published = 1 AND k0.keyword_text = 'los' AND i.journal_id = 7
GROUP BY o.submission_id
ORDER BY count DESC
LIMIT 500
My tech team just told me that the engine used is MyISAM, is it possible to do the following?
To eliminate the locks per table and optimize the memory and processor resources of the server, it is proposed to change from engine to InnoDB at least the tables that intervene in the mentioned query (I say at least because the performance improves substantially when handling this type de engine and we could evaluate to make the change on all the tables in the database).
This engine change was made in the test environment and the query execution time was below a few seconds, additionally when converting it to InnoDB it was possible to identify that 2 important indexes were needed, with which in the test environment they were achieved times of milliseconds, the indexes created were as follows:
ALTER TABLE ojs3.submission_search_objects
ADD INDEX submission_id_idx (submission_id ASC);
ALTER TABLE ojs3.submissions
ADD INDEX current_publication_id_idx (current_publication_id ASC);
Because this changes were made in the test environment we would like to know, if we make this change on production are we going to have any kind of problem with the platform?
… Sorry for the long response, but you guys are our only hope
Whoops, yes, those indexes should definitely be added! I’ll double-check our codebase to see if I can spot why they are missing. But yes, I definitely do recommend using InnoDB in general, and adding those indexes will not cause problems. I’ve posted this at Add indexes for search performance · Issue #6301 · pkp/pkp-lib · GitHub and please watch for me to add SQL there to generate the indexes – I’d recommend following the index naming convention I use there.
Regards,
Alec Smecher
Public Knowledge Project Team
There are definitely some performance improvements in 3.3.0-13 compared to 3.2.1-2, so it’s entirely possible that the issue you encountered will be resolved. I can’t guarantee it without knowing more details about the exact problem – but it’s a worthwhile first step. If it doesn’t work, we can explore next steps here.
Regards,
Alec Smecher
Public Knowledge Project Team