Hi
If I have to add references to the metadata after publishing the article, I have to use the so called ‘Extract and save references’, but then I have to accept some extra line spacing, an empty line between the references. Can I in any way prevent that?
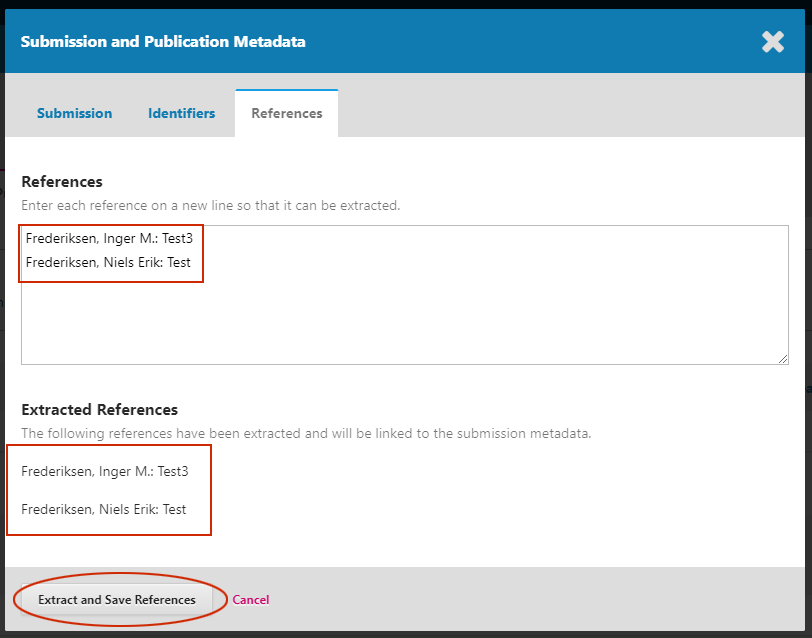
I’ve observed another error when using ‘Extracted References’. When I make the following extraction the number (21) in the very first reference is missing in the extracted references:
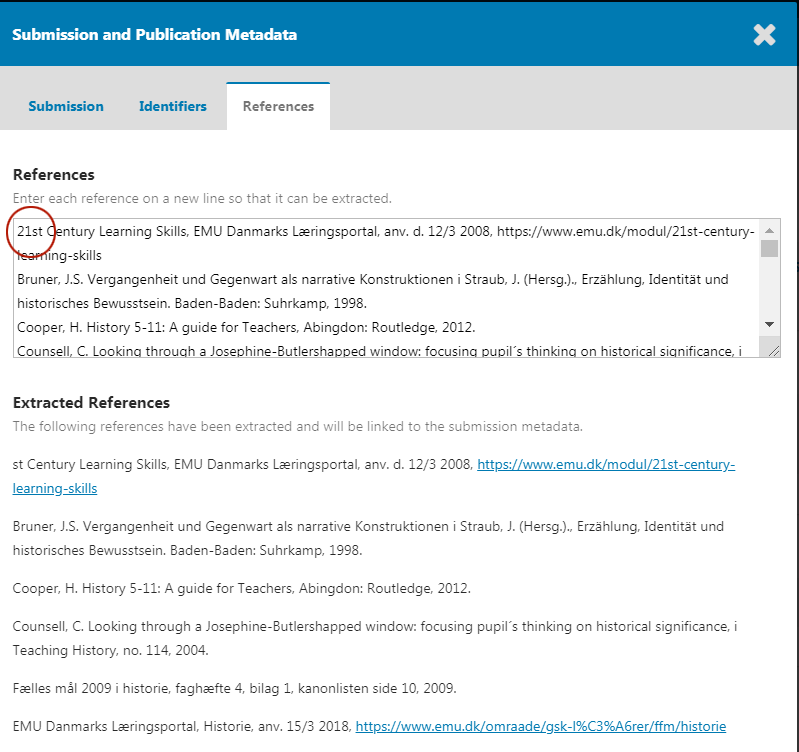
The problem is here:
We’re trying to strip out the numbering from numbered citations, but there isn’t clear definition of when the numbering ends. As the code stands, the number could optionally end with a period, close parenthesis, closing square brace, plus 0 or more spaces. The “21” in “21st” matches this and is stripped.
Our regex here needs to consider this.
In your original question, is the “empty line” between references present in the actual data (as a blank reference), or is this just a matter spacing within the display?
Thank you.
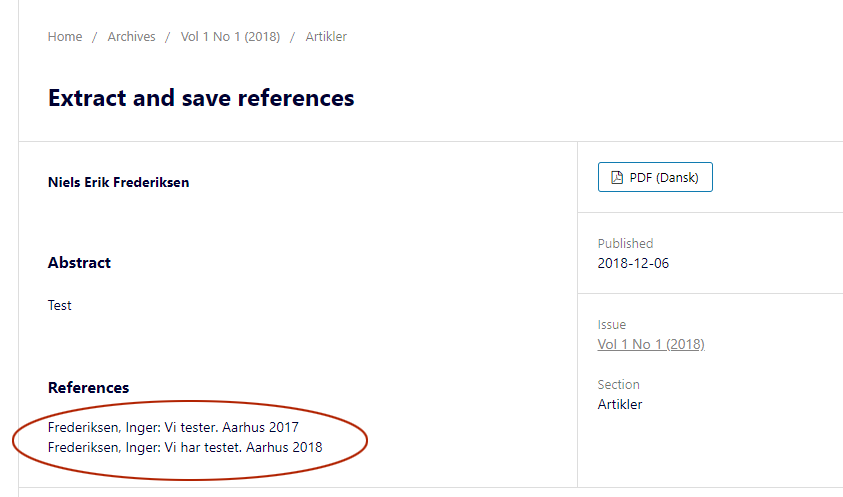
And to your last question, the “empty line” (as a blank reference) shows up after publishing. Below you see a before and after using the extract. That is the way it is presented to the reader
Before:
After:
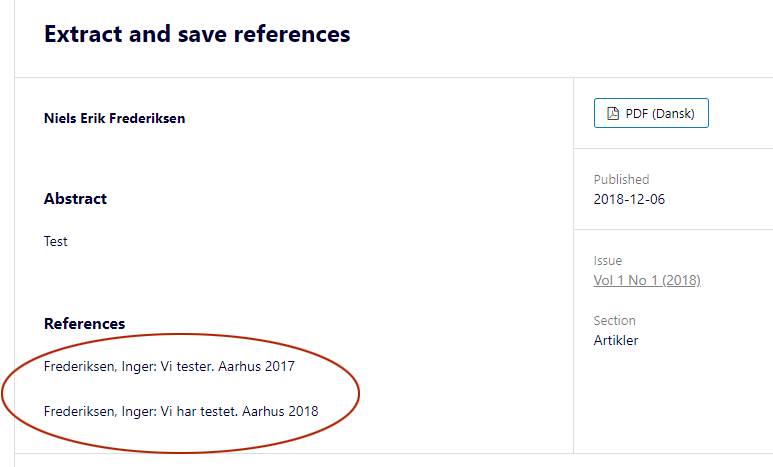
If you use your browser’s Web Inspector tool to examine the page source, you’ll find that these references are contained within p tags. You browser is applying default paragraph styling to the p tag.
<div class="item references">
<h3 class="label">References</h3>
<div class="value">
<p>Reference, Test: One. </p>
<p>Reference, Test: Two. </p>
</div>
</div>
To alter the display, add some custom CSS to override the margin property/properties which are adding this space, for example:
div.references div.value p {
margin-block-start: 0;
margin-block-end: 0;
}
Why don’t you use the ![]() tag instead?
tag instead?
The <br /> tag represents a structural markup tag rather than a semantic markup tag. The use of classing and ids on semantically relevant tags is preferred because it allows increased flexibility for styling (via CSS) and increased machine readability.
An alternate question could be: why were <p> tags used instead of <div> tags, or (even better) <li> tags? These references do not represent paragraph content in my mind.
I would really prefer a ![]() tag instead of the
tag instead of the ![]() tag. Then you can maintain the original formatting (see the above - before/after)
tag. Then you can maintain the original formatting (see the above - before/after)
The formatting is completely arbitrary; it is entirely based on your selected CSS.
That said, I think I see what you were getting at with respect to the <br /> tag. If references are parsed, they are displayed in <p> tags. If the references are not parsed, they are reformatted with <br /> tags separating each.
I think a better structure would be to always output them as an unordered list, classed to whether they are parsed or not.
The formatting would still be up to your CSS declarations, but the structure would be internally consistent and meaningful.
Hi @ctgraham
Here is an example of things going wrong. The references are broken down incorrectly due to the extra line spacing:
https://tidsskrift.dk/mediekultur/article/view/106133
Best
Niels Erik
This suggests that when the references were pasted into the textbox, there were line breaks within the references themselves. This tool requires “each reference on a new line so that it can be extracted”.
I remember making an attempt to guess whether the references were separated by on newline, or by two newlines, in order to accommodate references which might have internal linebreaks, but inconsistent data led me to ultimately fall back on just enforcing the instructions. The author or editor will need to cleanup the reference list to ensure it is each reference on a new line.
When I parsed the references of an article and then I look at the code of the article on my browser, all the “br” are changed in “li”. It is certainly more elegant but it generates problems for some databases that want to extract the metadata of the articles.
Where can I find the code to be retouched so that the br is not changed?
In general, what can I do to avoid this change generated by the “extract and save references” button?
Hi @StephenMAD,
It’s best not to post the same content multiple times, as it clutters the forum. Someone will respond to your other post: Change format of references - OAI - OJS 3
Thanks,
Alec Smecher
Public Knowledge Project Team
Sure. Sorry for that and thank you for your advice.