I have made a custom Endnote styling which can take care of the references in proper style required by the plugin. Download: http://jmri.org.in/files/J%20Med%20Res%20Innov.ens
Hi @Vitaliy I am working on a simple form for fill the imputs from the front of the final file.
The idea, is recive in an input the XML from your converter and fill the extra fields like the title abstract or keywords.
1 Like
Hi @josuevalrob
DOCX2JATS is more like an intermediate project which I managed in short-term for our goals. Its limitation includes relying on side stylesheets (TEIC). They are also used in meTypeset which in turn is included into Open Typesetting Stack. And much data are lost on XSL transformation. As I’m finishing JATS to PDF transformation for JATS Parser, I’m planning to return to writing better DOCX parser. it will be written in pure PHP so can be integrated into OJS without problems. This means that all meta-data for articles will come from OJS.
2 Likes
Dear @Vitaliy
Thank you for you great work!
But, i don’t can comleted it… Could you tell me, how is your work progressing on this project?
I will be grateful.
Kind regards,
McKonagan
I’ve just finished JATS Parser plugin for displaying JATS as HTML and PDF. I’m planning to start creating the main part of the DOCX to JATS converter in 2-3 weeks. The first version will transform all article body elements, like paragraphs, formatted text (italic, bold, underlined…), tables with rows and cells (including complex ones with merged cells), lists (including nested one), in-text references (with some limitations), figures, article’s sections with their titles. I’m expecting that all these elements would be transformed fully into JATS without the need of any manual correction. This work can take anywhere from 2 to 6 month.
If this plugin would be useful for the community, I’ll expand it for parsing reference list and different text style formatting (like text color, table cell width and height, footnotes). But it wouldn’t parse any metadata as it will write them into JATS XML from OJS.
1 Like
@Vitally
Thank you for your contributions to the OJS community. We are currently using your JATS Parser plugin to transform some legacy XML files within OJS to HTML.
We are very interested in your work on a DOCX to JATS converter. We’ve tested a number of workflows with the OTS stack, but we are still relying (for the most part) on manual encoding to XML for our journals publishing in full text. We are part of the community that would find the converter you are working on very useful.
Richard Higgins
IUScholarWorks | Scholarly Communication
Indiana University Libraries
https://scholarworks.iu.edu/journals/
1 Like
Hi @Vitaliy
I’m playing around with that parser actually. It’s a pretty helpful tool !
I have 2 questions:
-
The figure isn’t parsed in my test example https://biblio.unibe.ch/portale/elibrary/BOP/elbaum2.docx . I don’t know why. Maybe you?
-
Then do you have an example of a well formed conference Reference? I don’t find any on your github examples.
Thanks
Jan
The hard part here is played by TEIC XSLT stylesheets. I don’t know in which cases they miss parse embedded figures as simple paragraphs and cannot do anything here. For figures parsing is responsible this one: DOCX2JATS/graphics.xsl at master · Vitaliy-1/DOCX2JATS · GitHub
In second version of DOCX parser I’ll use own parsing mechanism, but I don’t know when it will be ready.
Example of conference paper reference: regex101: build, test, and debug regex
@Vitaliy
Thank you !
Hi Vitaliy
Do you may know how to set footnotes in word in a way they are parsed correctly? This xsl file DOCX2JATS/footnotes.xsl at master · Vitaliy-1/DOCX2JATS · GitHub is responsible I guess? Thanks.
jan
Hi @trace
Unfortunately, I’m not XSLT guy 
That’s TEIC Stylesheets, probably the best way would be to contact the developers: GitHub - TEIC/Stylesheets: TEI XSL Stylesheets
Also, I’m building new DOCX parsing library in PHP: GitHub - Vitaliy-1/docxToJats: DOCX to JATS XML Converter
Can you send me an example of DOCX with footnotes on my email and specify how it was generated (MS Word, Libreoffice, other tools) so I can add the support for them.
1 Like
@anupent
Do you have xml sample of reference for book chapter?
It should be compliant with AMA, something like: Chapter Author AA. Title of chapter. In: Editor AA, ed. Title of Work. Location: Publisher;Year:Page-Page.
1 Like
Just a heads up that I’ve integrated new DOCX to JATS library to OJS as a plugin and I think that in 2-3 weeks the first alpha release would be ready. Although it wouldn’t parse references until beta release but in many cases it’s already better than previous one and works through simple click. I’ll put instructions when alpha release will be ready for testing.
2 Likes
Our journal uses a lot of (merged) tables in published articles. When using Docs2Jats, the tables require further work manually. Some inquiries;
- Does the plugin work better with the table?
- In what stage of the editorial process it will be used?
- We are used to having header and footer in docs, is there a standard of docx to be parsed better?
- Can it parse APA citation format?
- Much better. Probably would not require manual correction, e.g. colspans and rowspans are determined correctly.
- Should be available in all stages, but I can limit it to production only in the future.
- Yep, I’ll include examples. For better parsing it should contain all common elements, like headings, table/figure caption, citations, footnotes, etc. Not all elements will be supported in the alpha release. Metadata will be added from OJS. Probably I also can upload figures automatically from DOCX if they have JPEG or PNG format.
- I’m thinking right now what to support. Probably it will be OOXML (native DOCX) citations, Zotero, internal parsed citations from OJS, by DOI or PMID. I’m not sure if I will try to parse references as a simple text in DOCX.
The produced JATS will be compatible with Texture. The example of JATS: docxToJats/test_jats.xml at d50922c45bdac92358481b5075d55a321456e788 · Vitaliy-1/docxToJats · GitHub
It requires a lot of work as I don’t use any 3-rd party libraries here.
1 Like
That is great. I cannot wait to try the plugin.
Is it a standalone plugin or a package of OldGregg update?
Standalone. It will require PHP 7.1+
1 Like
Dear @Vitaliy
We found this (read mark)
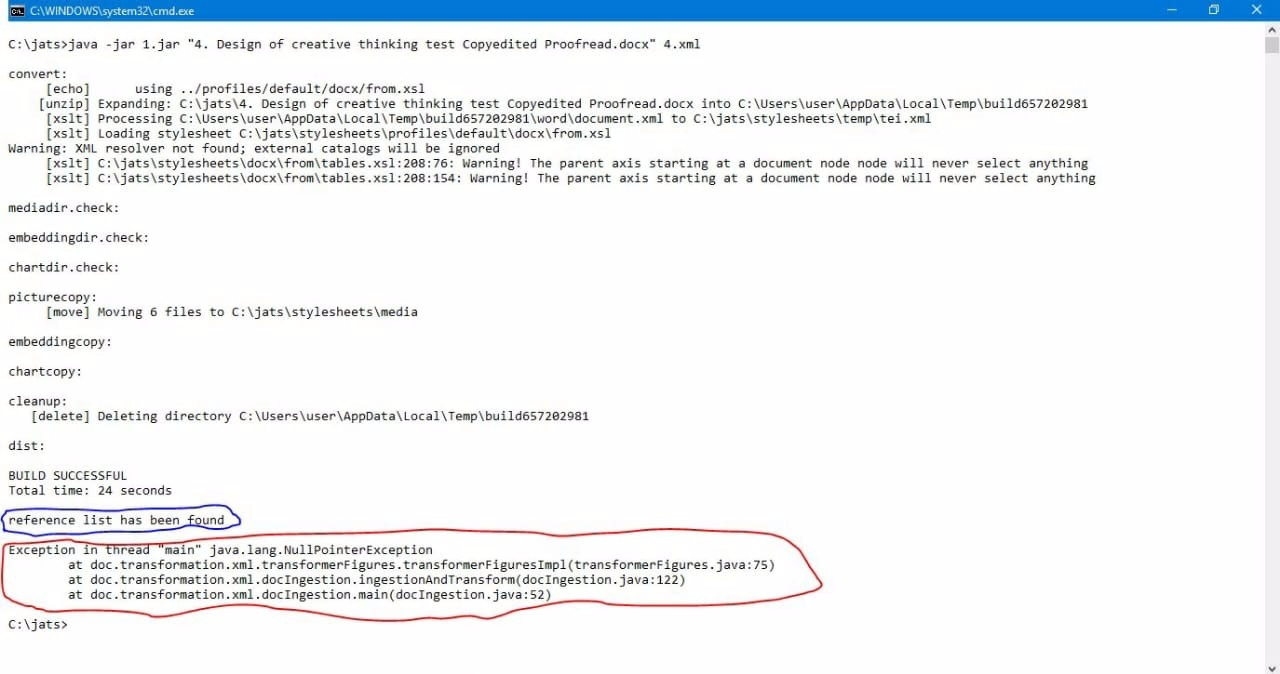
The xml was not generated. What might the problem?
Yes, there is a problem with parsing figures if it is the last element of the article or a section and doesn’t have notes. Is this your case?
1 Like