Yep. I too confirm that all looking fine.
Eventually, it loads. You are right about it
Thanks @varshilmehta
Hi all, this is resolved right?
The UI translation I did is still work in process, a wise thing to do would had been to put that in a different branch. It could be that a missing translation file could cause problems now. I have that, among many other things, on my work list, but I am still in the process of returning from summer vacation 
1 Like
Yes, it was resolved after deleting browser caches
First,
For chapter bibliography, I used the codes

It is displayed like this

What should be added to have it displayed properly? Name of editor and the book title show up
Second,
The image could not be displayed,

I tried uploading the image in google drive. How to deal with xlink?
Third,
What is the codes for article conference published in a proceedings?
Thanks so much
Hi @kawahyu,
I think the code for chapter is OK. I too write the same code. JatsParser by @Vitaliy might not be programmed to parse the name of book and editor. Vitaliy may look into the matter.
For image, I suggest you upload image as dependent file with the XML galley. For eg if the name of image is image1.jpg, then code it like:
<graphic xlink:href="image1.jpg">
Just use relative link.
I have never come across conference preceedings in reference, so I will see answer for it and record it for future use.
Regards
Sorry,where to upload the image? any required format e.g png?
Under galley, there a small triangle in front of each galley file. If you click that you will get options, click edit then you will get a button to upload dependent files.
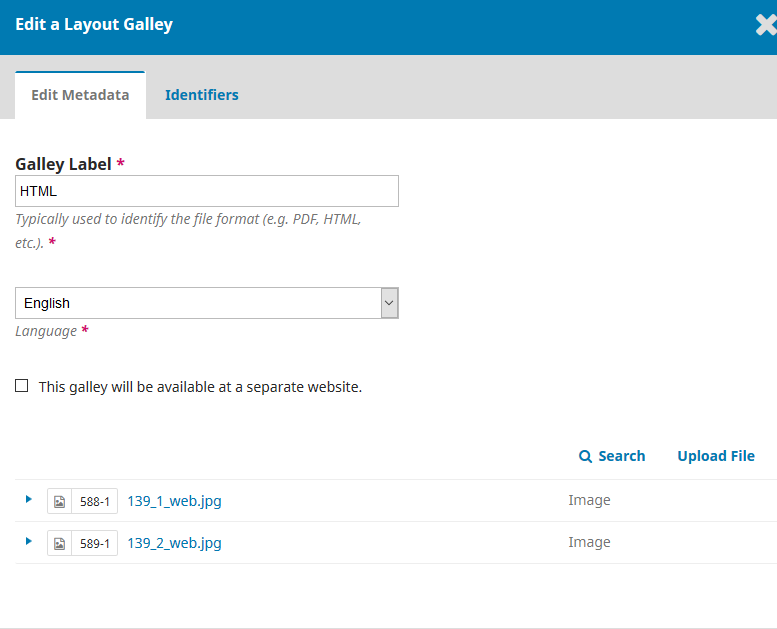
You can see my two files in the second picture.
139_1_web.jpg and 139_2_web.jpg
You can upload jpg or png files. I have not tried with other formats.
Regards.
1 Like
I am still using 3.0.1. I don’t find that Search and Upload File items.
Is it because ojs 3.0.1?
If so, is there patch which resolve it?
The absolute path also works. In fact, part of our old articles has URLs to figures pointed this way.
1 Like
The feature to add XML artwork files is here: Allow artwork files for XML galleys by ajnyga · Pull Request #1353 · pkp/ojs · GitHub. It is in 3.0.2 stable branch in github and of course in 3.1.
3 Likes
Hi @kawahyu,
This tag is premature closed:
<person-group person-group-type="editor"/>
And for displaying book title take a look at changes in this files:
Greetings to everyone.
As was planned, I have started the work on the 2nd version of the docx parser. What differences it makes in compare to previous version:
-
The parser wouldn’t contain any side projects. The code would be written in pure Java solely by me; with only native Java libraries.
-
It would parse all the data DOCX contains. Including, for example, real number of colspans and rowspans in table cells, references, etc. It was surprising for me how it is easy to achieve with Java.
-
I am planning to convert DOCX not only to JATS XML, but into latex/pdf also. In later versions I would add graphical interface for manual editing of parsing results.
I expect to release new alpha version in the next month:
4 Likes
Awesome. Will await patiently.
Eagerly waiting.
DOCX to JATS converter has been an important part of our production process.
Regards,
1 Like
Very happy to hear that.
Will it be able to use other citation format such as APA?
Alpha 2.0 version will support only native OOXML references (citation tool in Microsoft Word).
Full 2.0 release (planning to release in the late February) will support references as a simple list at the end of the document in AMA and APA formats. In the future releases I am planning to add support for zotero (maybe other citation tools as well), Harvard style as simple text and parsing the reference’s meta-data by the link to pubmed and crossref.
4 Likes
To extract the references out of word documents created with Zotero or Mendeley there exists an open source tool http://rintze.zelle.me/ref-extractor/ which might be helpful.
2 Likes
Citations are hardcoded inside document.xml (that exists inside DOCX archive). This is better for me to extract them by myself than to rely on 3rd party software, which I need incorporate in my Java code. It is not hard, actually. Just parse one more XML node type. But thanks for the link anyway.
1 Like