We’re currently on OJS 2.4.
Don’t know how this happened, but somehow a bunch of PDFs we bulk-uploaded some years ago are stored in OJS as TXT files, and also showing up in the “Download this PDF file” link as text files. So when you try to download the files via ‘“Download this PDF file” - Save File’, you get a lot of gobbledegook.
However, the files do display OK in the PDF window in view mode (with the pdj.js plugin), and you can view them OK as PDF via ‘“Download this PDF file” - Open With Adobe Acrobat’.
We tried changing the filename from TXT to PDF in the file structure, and also in the article_files table, but that didn’t work.
Any suggestions?
The key value will be the “File Type” you see when editing the file.
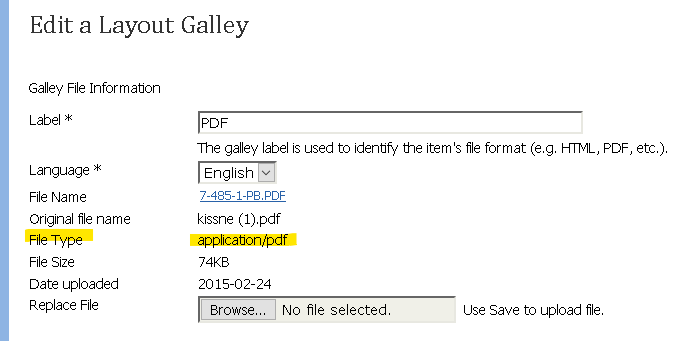
If this indicates “text/plain” instead of “application/pdf” (or similar), the file will be served up incorrectly.
This cannot be edited directly in the UI, but you can find this data in the article_files table, within the file_type column.
Thanks, ctgraham, this is very helpful and has put me on the right track - I hadn’t checkout out Edit a Layout Galley, so wasn’t aware of the “Replace File” option. That looks like the quickest way to fix the iffy records.
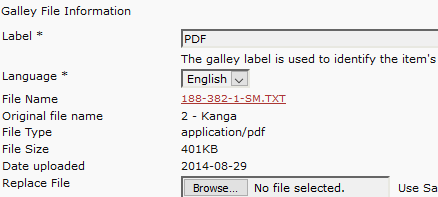
Here’s a screen print of the Galley File Info for one of our affected records; note the discrepancy between the Original File Name and File Type. Not the foggiest how that could have happened in the first place!
When uploading the file, the file extension record and served for the filename will be based on the filename which is uploaded (if available to the server).
The file type will be detected through examining the file’s contents looking especially at the structure of the first few bytes of the file.
It looks like in your case, there was no original file extension, e.g. “2 - Kanga” as opposed to “2 - Kanga.pdf”, so “.txt” was put in by default, but the system still recognized that it was a PDF file in content.