Currently OJS doesn’t load the full HTML DC.metadata of an article into , when viewing a PDF or HTML galley, but it should :o)
Thanks
Tobias
Currently OJS doesn’t load the full HTML DC.metadata of an article into , when viewing a PDF or HTML galley, but it should :o)
Thanks
Tobias
Metadata is on article detail page. It should be only on 1 location.
@Vitaliy, you’re absolutely right. My faulty reasoning!
Thanks
Tobias
Hm. Now I have to come back to this. I totally agree with Vitaliy, that there should be only 1 location for metadata. BUT: We underestimated google! The metadata might be shown completely on the article detail page, but for google this is a poor ranking, because content counts for the ranking. Since I uploaded our HTML galleys, the pages, that include the iframe with the HTML content weigh significantly more.
Furthermore:
To the HTML title of the pages, containing the iframe of the article, a localized string is added in front: (to be found here: locale/en_US/locale.xml:745). And this shows up in the google results – here the results of Google Alerts as an example (in German it’s »Anzeige von «).
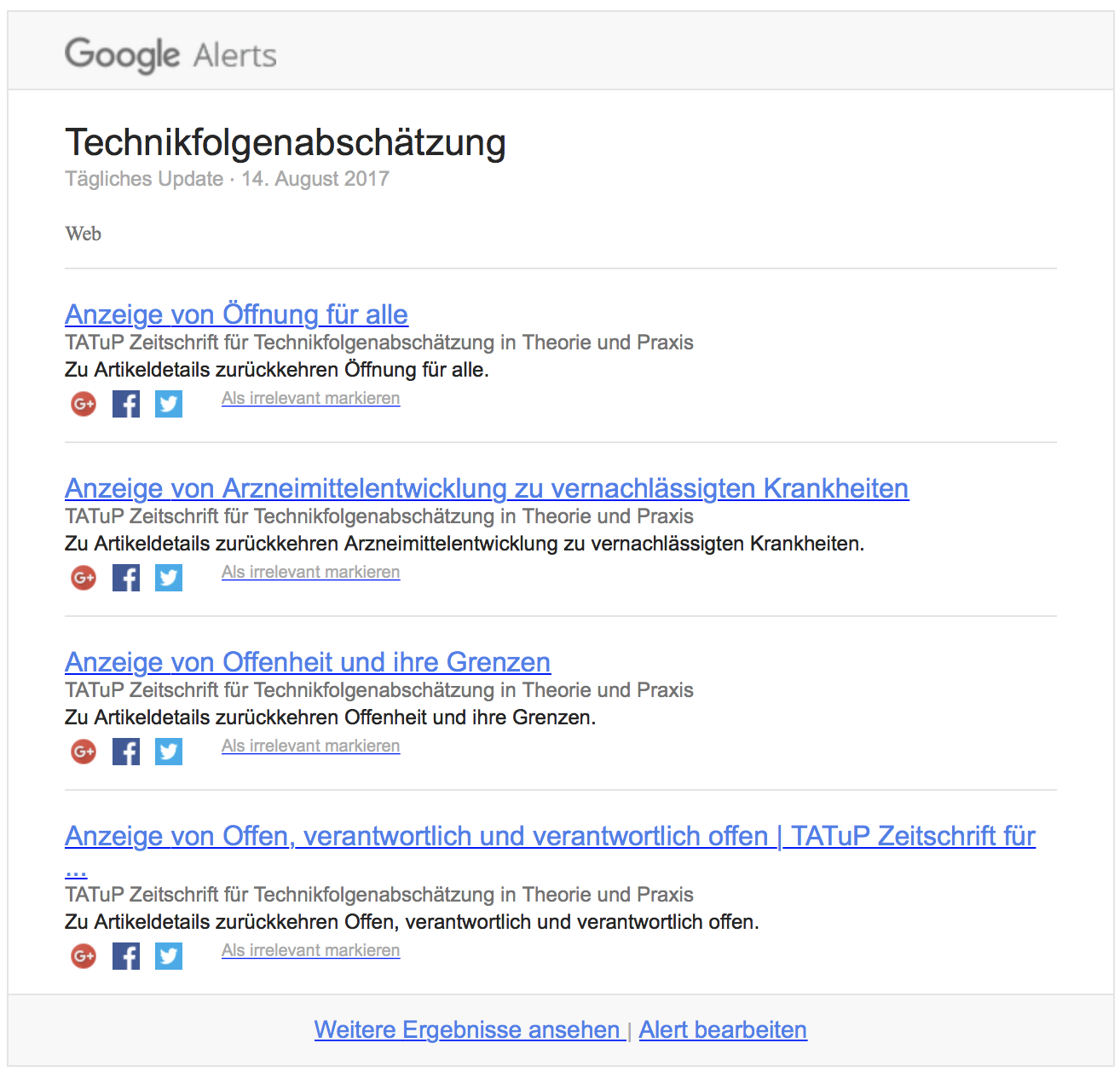
So I think from a SEO point of view it would be best, to integrate the article’s HTML full text to the article detail page.
Any suggestions on this?
Hi @twa,
does the google problem persist? Have you made any adjustments to OJS or the HTML-galleys?
best,
Carola
Hola, soy nuevo en el uso del OJS, respecto al tema, pienso que si se coloca toda la información en los detalles de los articulo no tiene sentido adjuntar los PDF, HTML u otro archivo ya que mostraría la misma información, solo debemos de insertar un resumen en los detalles del artículo. También hay que considerar que hay portales Web’s que nos linkean automáticamente a nuestra revista el cuál contribuye en nuestro posicionamiento SEO puede ser Latindex, por lo que hay que informarnos de su metodología para pertenecer a su Base de datos.
También pienso que para evitar que nuestro archivo HTML lo indexe Google debemos de utilizar el tag y . Ahora para evitar que google indexe donde está el código
Hi @bromero,
PDF and HTML files don’t contain the same information that article landing page does. For example, article metadata is presented on the latter page and it should be enough to avoid double indexing by Google Scholar or other similar services. The idea behind Galleys is to present attached to the article information like fulltext, data sets, supplemental materials, etc. The possibility for data duplication (like references, abstract) is up to the user, although it shouldn’t affect indexing in citation databases.
Regarding Google, they have an instruction for such cases: https://support.google.com/webmasters/answer/93710?hl=en
Have you tried them?